
How to Perform PCA in R: A Step-by-Step Tutorial Using prcomp()
To perform PCA in R, use the built-in prcomp() function: pca <- prcomp(data, scale = TRUE), then run summary(pca) to see how much variance each component explains. prcomp() handles centering, scaling, and the underlying singular value decomposition for you, and returns the loadings (pca$rotation) and component scores (pca$x) you need for any further analysis or visualization.
# Complete PCA in R script -- copy, paste, run top to bottom
# 1. Install and load required packages
install.packages(c("ggplot2", "factoextra"))
library(ggplot2)
library(factoextra)
#2. Load the data and check assumptions
data(USArrests)
str(USArrests)
cor(USArrests)
apply(USArrests, 2, shapiro.test)
#3. Scale the data (prcomp() can also do this inline with scale = TRUE)
data_scaled <- scale(USArrests)
head(data_scaled)
#4. Run PCA
pca <- prcomp(USArrests, scale = TRUE)
summary(pca)
pca$rotation
#5. Decide how many components to keep
plot(pca$sdev^2, type = "b", xlab = "Principal Component", ylab = "Eigenvalue", main = "Scree Plot")
fviz_eig(pca, addlabels = TRUE, barfill = "steelblue", barcolor = "steelblue",
linecolor = "firebrick", main = "Scree Plot: Variance Explained by Component")
pve <- pca$sdev^2 / sum(pca$sdev^2)
cum_pve <- cumsum(pve)
plot(cum_pve, type = "b", xlab = "Principal Component",
ylab = "Cumulative Proportion of Variance Explained")
#6. Visualize results
biplot(pca, scale = 0)
fviz_pca_biplot(pca,
geom.ind = "point",
col.ind = as.factor(state.region),
palette = "jco",
addEllipses = TRUE,
col.var = "black",
repel = TRUE,
legend.title = "Region") +
theme_minimal()Key Takeaways
- Principal component analysis (PCA) in R turns a set of correlated variables into a smaller set of uncorrelated principal components that capture most of the original variance.
- The built-in
prcomp()function is the preferred way to run PCA in R because it uses singular value decomposition (SVD), which is numerically more stable than the olderprincomp()function. - On the classic
USArrestsdataset, the first two principal components explain 86.75% of the total variance — verified directly from R output further down this page. - You can decide how many components to keep using a scree plot, the Kaiser rule (eigenvalue > 1), or a cumulative variance threshold — this tutorial shows all three and where they disagree.
- PCA is not the same as Factor Analysis. The comparison table below explains exactly when to use each one.

If you have a dataset with many correlated variables and want to find the ones that actually matter, reduce its complexity, and visualize it in two dimensions without losing the patterns hidden inside it — PCA in R is the tool for the job.
My name is Dr Zubair Goraya. I hold a PhD-level background in statistics and have used R for statistical consulting and research for several years. I ran into the same questions you probably have now — how many components to keep, how to read the prcomp() output, how to build a biplot with ggplot2 — while working through PCA for my own research, and I have since helped thesis and dissertation students work through the exact same problem.
What Is Principal Component Analysis (PCA)?
Principal component analysis is a statistical technique for dimensionality reduction. It takes a set of variables that are correlated with one another and re-expresses them as a smaller set of new, uncorrelated variables called principal components. The first principal component (PC1) captures the largest possible amount of variance in the data; the second (PC2) captures the largest amount of the variance left over after PC1, and so on, with each component orthogonal to the ones before it.

How PCA Works Under the Hood
You don't need to compute this by hand — prcomp() does it for you — but understanding the four steps helps you interpret the output correctly:
- Standardize each variable (mean 0, standard deviation 1) so no single variable dominates because of its scale.
- Compute the covariance matrix of the standardized variables, which captures how every pair of variables moves together.
- Decompose that matrix into eigenvectors (the direction of each principal component) and eigenvalues (how much variance that direction explains). The eigenvector with the largest eigenvalue is PC1.
- Project the original data onto the new eigenvector axes. This produces the component scores — the new coordinates for every observation in the reduced space.
prcomp() performs this using singular value decomposition (SVD) rather than direct eigendecomposition of the covariance matrix, which is the same result reached through a numerically more stable route — this is why prcomp() is preferred over princomp() in R.
What You Need Before Running PCA in R
PCA only works on numeric, continuous variables. You'll use:
prcomp()— built into base R'sstatspackage, no installation needed.ggplot2— for the custom scree plot and biplot in this tutorial.factoextra— aggplot2-based wrapper that turns PCA output into publication-ready plots with a single function call.
install.packages(c("ggplot2", "factoextra"))
library(ggplot2)
library(factoextra)This tutorial uses USArrests, a dataset built into R covering violent crime rates and urban population percentage for all 50 US states in 1973 — the same dataset used in An Introduction to Statistical Learning, so you can cross-check your output against a well-known reference.
Step 1: Check Your PCA Assumptions in R
PCA assumes your variables are numeric, continuous, linearly related, and reasonably normally distributed. Confirm this before you run anything:
data(USArrests)
str(USArrests) # numeric and continuous?
cor(USArrests) # linearly related?
apply(USArrests, 2, shapiro.test) # normally distributed?Running a Shapiro-Wilk normality test on each variable shows that UrbanPop is the only variable that does not significantly depart from normality (p = 0.977); Murder, Assault, and Rape all return p-values below 0.05:
| Variable | W | p-value | Significant? |
|---|---|---|---|
| Murder | 0.957 | 0.067 | Yes |
| Assault | 0.952 | 0.041 | Yes |
| UrbanPop | 0.977 | 0.439 | No |
| Rape | 0.947 | 0.025 | Yes |
PCA is fairly robust to mild non-normality, especially with n = 50, so this tutorial proceeds with all four variables rather than dropping any. If your own data fails normality more severely, consider a transformation first, or revisit whether PCA is the right tool at all — see the PCA vs. Factor Analysis comparison further down this page.
Step 2: Scale and Center Your Data
Murder, Assault, and Rape are measured per 100,000 residents while UrbanPop is a percentage — different scales entirely. Without scaling, Assault (values up to 337) would dominate the first component purely because of its larger numbers, not because it is more important. prcomp() has a built-in scale. argument that handles this for you, but you can also normalize the data manually first using Z-score standardization if you want to inspect the scaled values:
data_scaled <- scale(USArrests)
head(data_scaled)Step 3: Run PCA in R With prcomp()
Now run PCA on the full four-variable dataset, with scaling handled inline:
pca <- prcomp(USArrests, scale = TRUE)
summary(pca)This is the actual summary(pca) output for USArrests:
| Importance of components | PC1 | PC2 | PC3 | PC4 |
|---|---|---|---|---|
| Standard deviation | 1.5749 | 0.9949 | 0.5971 | 0.4164 |
| Proportion of Variance | 0.6201 | 0.2474 | 0.0891 | 0.0434 |
| Cumulative Proportion | 0.6201 | 0.8675 | 0.9566 | 1.0000 |
PC1 alone explains 62.0% of the total variance; PC1 and PC2 together explain 86.75%. That means you can reduce four variables down to two principal components and still retain most of the information in the original data.
Looking at pca$rotation shows what each component represents: PC1 loads heavily and negatively on Murder (-0.536), Assault (-0.583), and Rape (-0.543), with a smaller loading on UrbanPop (-0.278) — so PC1 is best read as an overall violent crime axis. PC2 loads almost entirely on UrbanPop (0.873), making it an urbanization axis largely independent of crime rate.
Step 4: Decide How Many Components to Keep
There is no single universal rule. In practice, researchers triangulate using three methods — and on this dataset, they don't all agree, which is itself a useful teaching example.
Method 1: The Scree Plot
plot(pca$sdev^2, type = "b", xlab = "Principal Component", ylab = "Eigenvalue", main = "Scree Plot")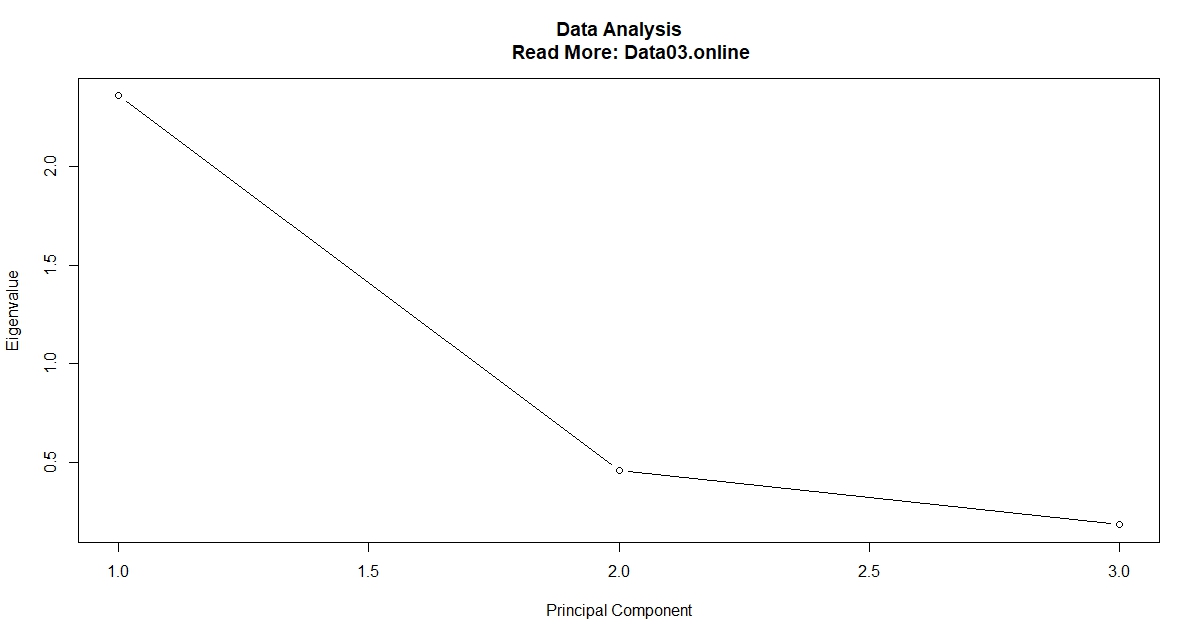
Look for the "elbow" — the point where the line flattens out. The components before the elbow are worth keeping; the ones after add little.
The ggplot2 / factoextra Version
For a publication-ready scree plot built on ggplot2 instead of base R graphics, factoextra gives you a single-line solution:
fviz_eig(pca, addlabels = TRUE, barfill = "steelblue", barcolor = "steelblue",
linecolor = "firebrick", main = "Scree Plot: Variance Explained by Component")fviz_eig() returns a standard ggplot object, so you can layer on any further ggplot2 theming (+ theme_minimal(), custom labels, color palettes) exactly as you would with any other ggplot2 chart.
Method 2: The Kaiser Rule (Eigenvalue > 1)
The Kaiser criterion says: keep any component whose eigenvalue (standard deviation squared) exceeds 1. On this dataset:
| Component | Eigenvalue | Keep under Kaiser rule? |
|---|---|---|
| PC1 | 2.480 | Yes |
| PC2 | 0.990 | No (just under 1) |
| PC3 | 0.357 | No |
| PC4 | 0.173 | No |
This is a good example of why the Kaiser rule shouldn't be used in isolation: PC2's eigenvalue (0.990) is essentially 1, so a strict cutoff would discard a component that still explains nearly a quarter of total variance and has a clear, interpretable meaning (urbanization). Most applied researchers would retain PC2 here despite the Kaiser rule's technical "no."
Method 3: Cumulative Variance Threshold
pve <- pca$sdev^2 / sum(pca$sdev^2)
cum_pve <- cumsum(pve)
plot(cum_pve, type = "b", xlab = "Principal Component",
ylab = "Cumulative Proportion of Variance Explained")
A common threshold is 80–90% cumulative variance. Here, two components clear 80% (86.75%), so retaining PC1 and PC2 is the most defensible choice across all three methods combined.
Step 5: Visualize PCA Results — Biplot in R
A biplot overlays the component scores (observations) and the loadings (original variables) on the same PC1/PC2 plane.
Base R Biplot
biplot(pca, scale = 0)
PCA Biplot With ggplot2 (factoextra)
The base R biplot is functional but not very customizable. For a ggplot2 biplot with colored points, confidence ellipses, and repelled labels, use fviz_pca_biplot():
fviz_pca_biplot(pca,
geom.ind = "point",
col.ind = as.factor(state.region),
palette = "jco",
addEllipses = TRUE,
col.var = "black",
repel = TRUE,
legend.title = "Region") +
theme_minimal()Because fviz_pca_biplot() returns a ggplot object, every ggplot2 layer works: swap palette, add + labs(title = "..."), or change the theme without touching the underlying PCA math.

Southern states cluster toward high values on PC1 (higher violent crime), while Western states spread further along PC2 (higher urbanization) — exactly the two axes the loadings predicted in Step 3.
PCA vs. Factor Analysis: What's the Difference?
Students frequently confuse PCA with Factor Analysis because both reduce a large set of variables down to a few. They are not interchangeable, and using the wrong one is a common mistake in thesis methodology chapters:
| PCA | Factor Analysis | |
|---|---|---|
| Goal | Maximize explained variance; data reduction | Identify latent constructs that cause the observed variables |
| Variance modeled | All variance (common + unique) | Only shared (common) variance; unique/error variance is separated out |
| Assumes a latent variable? | No — purely a mathematical transformation | Yes — assumes observed variables reflect underlying factors |
| Rotation | Not typically used | Often rotated (varimax, promax) for interpretability |
| R function | prcomp() | factanal() or psych::fa() |
| Use when | You want to reduce dimensionality or visualize structure | You're testing a theory about what underlying constructs explain your items |
If you're building a scale to measure a psychological construct (anxiety, job satisfaction, brand loyalty), you almost certainly want Exploratory Factor Analysis, not PCA — even though both are run on similarly structured survey data.
How to Report PCA Results in APA Style
For a thesis or journal manuscript, your methods and results sections should report PCA in a standard format. Based on the USArrests output above, here is a template you can adapt:
Sample write-up:
"A principal component analysis (PCA) was conducted on four crime-related variables (Murder, Assault, UrbanPop, Rape) using the prcomp() function in R (R Core Team). Variables were standardized prior to analysis. Using the Kaiser criterion (eigenvalue > 1) in combination with a scree plot and an 80% cumulative variance threshold, two components were retained. PC1 explained 62.0% of the variance and was driven primarily by Murder, Assault, and Rape (loadings of -0.54, -0.58, and -0.54, respectively), suggesting a general violent crime dimension. PC2 explained an additional 24.7% of the variance and loaded almost exclusively on UrbanPop (0.87), representing an urbanization dimension. Together, the two components accounted for 86.75% of total variance."
Always include a loadings table (as shown in Step 3) and either a scree plot or a cumulative-variance plot as a figure when reporting PCA in a formal write-up — reviewers and committee members expect to see the basis for your retention decision, not just the final component count.
Further Analysis: Using PCA Output Downstream
Once you have component scores (pca$x), they become inputs for other analyses — for example, as features for k-means clustering on a reduced, decorrelated dataset, or to detect multicollinearity before fitting a regression model.
Conclusion
You've now run a complete PCA in R: checking assumptions, scaling the data, fitting prcomp(), choosing how many components to keep using three different methods, visualizing results in both base R and ggplot2, distinguishing PCA from Factor Analysis, and reporting the output in APA format. The same workflow applies directly to your own dataset — just swap USArrests for your data frame.
Frequently Asked Questions
What is the best R package for PCA?For most users, the built-in prcomp() function (stats package) is sufficient and is preferred over princomp() for its numerical stability. For richer visualization, pair it with factoextra. For multivariate exploratory work beyond PCA — including correspondence analysis — FactoMineR is the more comprehensive package.
Use plot(pca) for a quick scree plot, biplot(pca) for a base R biplot of scores and loadings, or factoextra::fviz_pca_biplot(pca) for a fully customizable ggplot2 version with color, ellipses, and labels, as shown in Step 5 above.
prcomp() returns an object of class "prcomp" containing: sdev (standard deviations of each component), rotation (the loadings matrix), x (the component scores for each observation), and center/scale (the centering and scaling values used).
princomp() uses spectral (eigen) decomposition of the covariance matrix. prcomp() uses singular value decomposition (SVD) of the data matrix directly, which has slightly better numerical accuracy. R's own documentation recommends prcomp() for this reason.
There's no universal rule. Triangulate using a scree plot (look for the elbow), the Kaiser criterion (eigenvalue > 1), and a cumulative variance threshold (commonly 80–90%) — Step 4 above shows all three applied to the same dataset, including a case where they disagree.
Can PCA be used on categorical variables?Standard PCA requires numeric, continuous variables. For categorical data, use Multiple Correspondence Analysis (MCA) instead, available via FactoMineR::MCA(), which applies the same dimensionality-reduction logic to a contingency table of category frequencies.
The three most frequent errors: (1) skipping scale = TRUE, which lets large-magnitude variables dominate the first component; (2) not checking for missing values or outliers beforehand, which distorts the covariance matrix; and (3) misreading the scree plot elbow or ignoring loading signs when interpreting what a component represents.
PCA is widely used for image compression, facial recognition feature extraction, gene expression analysis in bioinformatics, customer segmentation in marketing, and as a preprocessing step before clustering or regression to remove multicollinearity.
If you're working through PCA, Factor Analysis, or any other multivariate technique for a thesis or dissertation and want a second pair of eyes on your output, get in touch below.
Get PCA / Statistics Help on WhatsApp Join Our Community